Various TensorFlow APIs for Python
Tuesday March 21, 2017
An early perception of TensorFlow was that the API was quite low-level.
"meaning you’ll be multiplying matrices and vectors."
TensorFlow offers ops for low-level operations, and from the beginning programmers used those low-level ops to build higher-level APIs.
To paraphrase Paul Graham:
"if you have a choice of several [APIs], it is, all other things being equal, a mistake to program in anything but the [highest-level] one."
You don't need to be a Lisp hacker to make it easier to use TensorFlow the way you want by writing new functions and classes, and you probably should.
But because TensorFlow had already done the obviously hard work of making low-level things work, it was relatively easy for lots of people to attempt the subtly hard work of designing higher-level APIs.
This led to a proliferation of Python APIs, which can sometimes be confusing to track.
Things are still moving around and settling a bit, but Google is communicating a pretty clear plan for official Python APIs for TensorFlow.
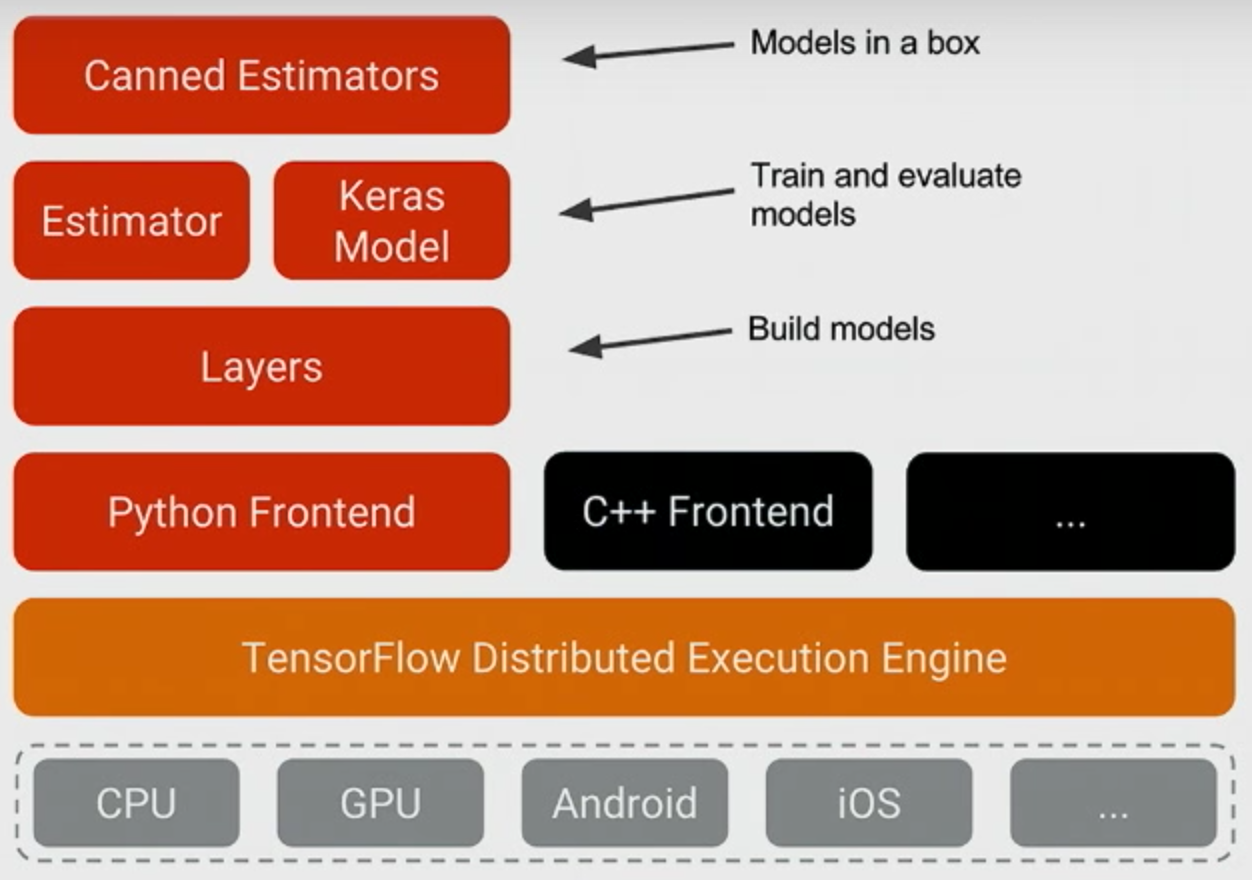
(Image from the TensorFlow Dev Summit 2017 keynote.)
This plan changes some names and rearranges things slightly, but it's an incremental development of things that have existed for a while. We can look at how things have developed over time both for what's becoming official TensorFlow API and some of the projects that still exist outside official TensorFlow.
Python Frontend (op level)
You can continue to use TensorFlow's low-level APIs.
There are ops, like tf.matmul and tf.nn.relu, which you might use to build a neural network architecture in full detail. To do really novel things, you may want this level of control. But you may also prefer to work with larger building blocks. The other other APIs below will mostly specialize in this kind of application.
There are also ops like tf.image.decode_jpeg (and many others) which may be necessary but don't necessarily relate to what is usually considered the architecture of neural networks. Some higher-level APIs wrap some of this functionality, but they usually stay close to the building of network architectures and the training of such networks once defined.
Layers (as from TF-Slim)
TF-Slim has a number of components but it looks like essentially we're seeing the following: tf.contrib.slim.layers became tf.contrib.layers becomes tf.layers.
Sergio Guadarrama, one of the TF-Slim authors, generously confirmed that TensorFlow is converging on a layers API and implementation along these lines, but warns that there can still be some differences. He points out that tf.contrib.layers have arg_scope, while tf.layers don't.
This layers API provides a first higher level of abstraction over writing things out by individual ops. For example, tf.layers.conv2d implements a convolution layer that involves multiple individual ops.
Other parts of TF-Slim are likely also worth using, and there is a collection of models that use TF-Slim in the TensorFlow models repository.
Historical note: It looks like before calling them layers, TF-Slim overloaded the word "op" for their layer concept (see earlier documentation).
TF-Slim is in the TensorFlow codebase as tf.contrib.slim.

Estimator (as from TF Learn)
Distinct from TensorFlow, the scikit-learn project makes a lot of machine learning models conveniently available in Python.

A key design element of scikit is that many different models offer the same simple API: they are all implemented as estimators. So regardless of whether the model is linear regression or a GBM, if your instantiated scikit-learn model object is called estimator, you can do all of these:
estimator.fit(data, labels) # train
estimator.score(data, labels) # test
estimator.predict(data) # run on new dataThe estimator API for TensorFlow is directly inspired by scikit-learn, though implemented quite independently. Here's nearly equivalent TensorFlow code, assuming you have a TensorFlow estimator model instantiated as estimator:
estimator.fit(data, labels) # train
estimator.evaluate(data, labels) # test
estimator.predict(data) # run on new dataThe only thing that changed in the code is scikit-learn's score method becomes evaluate, which I think is going to do a lot of good for the self esteem of TensorFlow models.
There are other differences too. In scikit-learn, usually models have an idea of training "until done"—but in TensorFlow, if you don't specify a number of steps to train for, the model will go on training forever. TensorFlow estimators also do a lot of things by default, like adding TensorBoard summaries and saving model checkpoints.
The estimators API started as skflow ("scikit-flow") before moving into the TensorFlow codebase as tf.contrib.learn ("TF Learn") and now the base estimator code is getting situated in tf.estimator and documentation is accumulating.
Keras Model (absorbing Keras)
Keras was around before TensorFlow. It was always a high-level API for neural nets, originally running with Theano as its backend.
After the release of TensorFlow, Keras moved to also work with TensorFlow as a backend. And now TensorFlow is absorbing at least some aspects of the Keras project into the TensorFlow codebase, though François Chollet seems likely to continue championing Keras as a very fine project in its own right. (See also his response to a Quora question about any possible relationship between TF-Slim and Keras.)
Once specified, Keras models offer basically the same API (fit/evaluate/predict) as estimators (above).
Keras is appearing in the TensorFlow codebase as tf.contrib.keras and should move to tf.keras at TensorFlow 1.2.

Canned Estimators
Canned estimators are concrete pre-defined models that follow the estimator conventions. Currently there are a bunch right in tf.contrib.learn, such as LinearRegressor and DNNClassifier. There are some elsewhere. For example, kmeans is in tf.contrib.factorization. It isn't clear to me exactly where all the canned estimators will eventually settle down in the API.
Sonnet
Google's DeepMind group released their Sonnet library, which is used in the code for their learning to learn and Differentiable Neural Computer projects. Sonnet isn't part of TensorFlow (it builds on top) but it is a Google project, so I'm including it in the list here. Sonnet has a modular approach compared to that of Torch/NN. Also they have a cool logo.

Other APIs
All the APIs that follow are not part of the official TensorFlow project. I guess you could use them.

Pretty Tensor
Pretty Tensor is still a Google project, so it might be worth checking out if you really like fluent interfaces with lots of chaining, like d3.
TFLearn
The confusingly named TFLearn (no space; perhaps more clearly identified as TFLearn.org) is not at all the same thing as the TF Learn (with a space) that appears in TensorFlow at tf.contrib.learn. TFLearn is a separate Python package that uses TensorFlow. It seems like it aspires to be like Keras. Here is the TFLearn logo:

TensorLayer
Another one with a confusing name is TensorLayer. This is a separate package from TensorFlow and it's different from TensorFlow's layers API.

ImageFlow
ImageFlow was supposed to make it easier to do image work with TensorFlow. It looks like it's abandoned.
My recommendation is to use the rich APIs available inside TensorFlow. You shouldn't have to import anything else, with the possible exception of Keras if you like it and are working before the Keras integration into TensorFlow is complete.
Thanks to Googler and TF-Slim developer Sergio Guadarrama for clarifying the development of the layers APIs, and thanks to Andreas Mueller of scikit-learn for his summary of the relation between scikit-learn and TensorFlow.