Some theory and practice for data cleaning
Saturday January 4, 2014
Data cleaning can refer to many things. I'll mention some important data structure ideas elucidated by Wickham, and then spend more time on the topic of assumptions and data coherence, and how data cleaning happens in practice. By the end, we may achieve some hope of getting reasonably meaningful results from our data.
Hadley Wickham has made available very good explanations (paper, slides, presentation) of what he calls "tidy data". Tidy data has variables stored in columns, observations in rows, and a single type of experimental unit per dataset. This framework is both a good idea in its own right, and it also let's you easily use a lot of very good data manipulation and graphics tooling in R - much of which is also due to Wickham.
The idea of tidy data provides guidance in how to begin restructuring data for analysis. What, then, are the data problems that are not fundamentally due to data structure?
Harry Frankfurt has a charming essay, published as a small book, called On Bullshit.

The book is quite funny, and it also provides a useful definition of bullshit: communicating without concern for the truth, or with "indifference to how things really are" (p. 34). It claims, and may be correct, that "bullshit is a greater enemy of the truth than lies are" (p. 61).
A lot of data has this bullshit lack of regard for facts, and it is this sort of data problem that I am principally concerned with. This class of problem can arise all throughout the data quality framework of McCallum, which calls for data to be complete, coherent, correct, and accountable, though typically coherence admits most easily of self-contained testing.
The vast majority of data problems are not intentionally introduced. They appear by accident or through miscommunication, and because they were not detected and corrected. It isn't easy to completely assure the quality of a data set, and in any event there frequently aren't resources allocated to thorough checking. Data can seem quite authoritative when viewed from a distance - why check it?
It would be nice to have at least two individuals (or teams) develop the same data product in parallel, collaborating on a shared set of business rules, so that they can check their final results against one another, and have a further QA step before release. But the model of a lone individual hacking out a spreadsheet without so much as a second look before release is unfortunately common. When it comes to open data initiatives, for example, it sometimes seems that data is scooped from a trough and thrown into the world.
Data dirtiness could be addressed at creation, and we should keep this in mind when creating data ourselves. Keep it clean! But as it is often not, it is incumbent on the analyst to be diligent in checking and addressing issues with the data under analysis. Be aware of the process you are a part of.
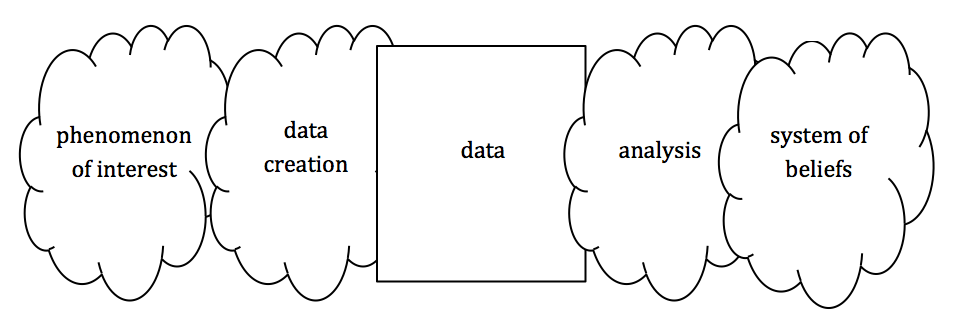
All of analysis is coming up with beliefs. These beliefs are based on implicit models. Probably the most common cause of initial results from data is error. This is especially true for interesting results, but it applies everywhere. For example:
$ wc -l data.csv
5 data.csv
A common reading of this would be that the file data.csv contains five lines, or rows. However, this is not necessarily the case:
> read.table("data.csv")
V1
1 I think...\nthat...\nit's good!
2 dunno
3 It's bad!
There are three rows here. What happened? There was a problem with our assumptions, or with the implicit model we used. The program wc does not tell us how many lines there are in a file. It tells us how many newline characters ("\n") there are - how many times there is a byte that goes 00001010. The implicit assumption was that each line of data had exactly one newline character. It was a linear model: "number of lines in the file = 1 * number of newline characters in the file + 0". Notice that the model is fine, and the result is also fine - if the assumption holds. But often, we aren't even aware of the assumption, we aren't aware of the implicit model, and we don't check what we're relying on.
The example with wc is about being aware of levels of abstraction and how they interact with your tools so as to not draw incorrect conclusions. The sorts of assumptions more closely related to what we usually think of as clean data issues are things like:
- this is everything we should include
- there's exactly one record per entity
- the line items add up to the subtotals
- these are all in the same units
- these dates are all in order
A good place to start with a new data set is by checking for problems that could not possibly occur. Very often, you will find that they occur anyway. A common example is checking unique IDs. They are frequently not.
When it comes to checking things, I recommend never checking anything once. When you become aware of something that should be true about your data, write a check that embeds itself forever in your code. Very occasionally there are performance concerns, but almost always correctness is more important. The "theory" here is that the strength of the computer - automating things - should be leveraged to reduce human cognitive load while increasing confidence in results. Include explicit assumption tests in analysis code.
Checks can also be included for things that need not be true - for intermediate results, totals, and so on. Analysis code may have many steps, and it may not be obvious how a change at an early step affects things downstream. Including something as simple as, for example, stopifnot(sum(data$total)==9713) at the bottom of a script will alert you if you introduce something that changes this - especially useful to know when you think you're making changes that don't.
Another way to make this point about coded checks is that comments in code should be avoided for describing data.
# There are 49 missing values. # NO stopifnot(sum(is.na(my.data))==49) # YES
The comment is instantly out of date if something changes, and likely forgotten. The code will automatically let you know if something changes. This is vastly superior.
Quite a lot of checks can be written very simply - for example, the often-neglected checks around merges (joins). Many more complex checks are included in the assertive package available for R, which has things like assert_all_are_credit_card_numbers and assert_all_are_isbn_codes, for example.
Many checks will be domain-specific, but it's common to have univariate distributions to investigate. The tails (outliers) are often the result of some data problem, and we should be grateful when this is the case, because it's much easier to notice than if the spurious data is throughout the range of correct values. Of course the tails are also important places to take care because they will have dramatic effects on many types of analysis.
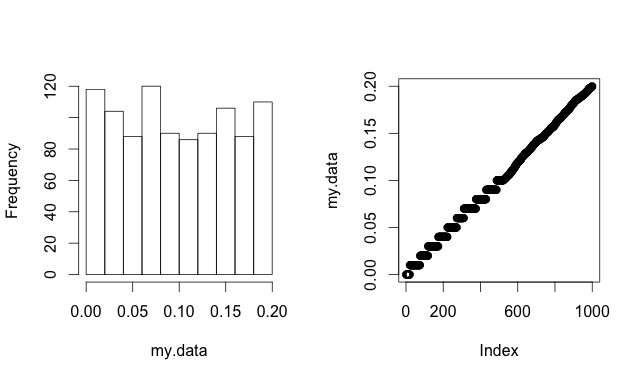
This is a place where data visualization is an essential tool for data cleaning. Histograms can show some information about a distribution. I often prefer what Cleveland calls quantile plots (different from QQ plots) which can be easily made in R (with index rather than quantile labels) as plot(sort(my.data)). These plots do not depend on bin size - every data point is shown. Much more of the fine structure of a distribution can be quickly and easily taken in. This image shows a contrived data set two ways, illustrating the occasional advantage of quantile plots.
Many data checks might be called "reality checks". It is worth being aware of the danger of crossing over into "unreality checks" when our biases overrule the data. There is often an essentially Bayesian flavor to checking data. We suspect that a janitor's salary of $100,000,000 is not correct because of our prior beliefs about the world. Probably we are correct to say that this data is bad. But if we are over-zealous in eliminating or adjusting data that seems wrong, we may end up eliminating or adjusting the most interesting correct data as well. Care must be taken to make choices that maximize the information content of our data.
When possible, fix data. For example, adult heights entered sometimes in feet and sometimes in centimeters can be easily adjusted to either by machine because their ranges do not overlap. This is probably better than dropping all of either type, but choices like this may not always be easy.
It's not uncommon to hear it said that 80% of a data project is data wrangling work. But this doesn't mean that you can do data cleaning Monday through Thursday and analysis on Friday. It is a good idea to think about data cleaning up front, but there are often practical concerns about the scope of the data cleaning work.

> ncol(my.data) [1] 1274

In addition, it's often the case that you discover data problems in the course of analysis. (Sometimes, this is the only way that data problems are discovered.) You likely can't predict at the outset exactly which fields you'll need or how problems will arise. A simple example is that two columns may each look fine, but if analysis calls for their ratio, absurd data problems can become evident.
Another concern is that data issues are often stubbornly non-general. We would like to aim to generalize, but may find that ad hoc solutions are sometimes unavoidable. We are left aiming to generalize, preparing to specialize.
Probably data cleaning will remain art and science, entangled with analysis, and resistant to fully generalizable principles. As usual:
The difference between theory and practice is larger in practice than it is in theory.
This post was originally hosted elsewhere.