🐉 Scylla of overfitting
⛵ Ulysses' compass 🧭
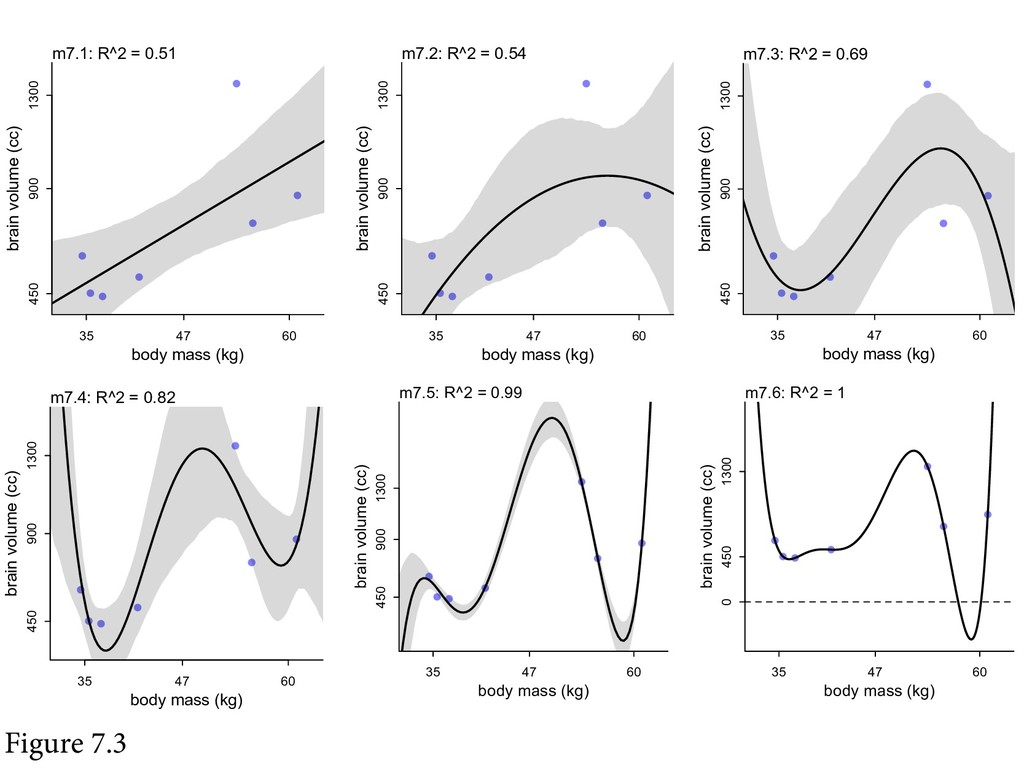
🌪 Charybdis of underfitting
from math import log
# Truth (as in Problem 7E1)
p = [0.7, 0.3] # heads, tails# Entropy, H(p)
H = lambda p: -sum(p_i * log(p_i) for p_i in p)
H(p) # 0.6108643020548935# Candidate "models"
q = [0.5, 0.5]
r = [0.9, 0.1]# Cross-Entropy, H(p, q), xH here because Python
xH = lambda p, q: -sum(p_i * log(q_i) for p_i, q_i in zip(p, q))
xH(p, q) # 0.6931471805599453
xH(p, r) # 0.764527888858692# KL Divergence, D(p, q)
D = lambda p, q: sum(p_i * log(p_i/q_i) for p_i, q_i in zip(p, q))
D(p, q) # 0.08228287850505178
D(p, r) # 0.15366358680379852# D(p, q) = H(p, q) - H(p)
D(p, q) == xH(p, q) - H(p) # True# Data
d = [0, 0, 1] # heads, heads, tails# Log probability (likelihood) score
S = lambda d, p: sum(log(p[d_i]) for d_i in d)
S(d, q) # -2.0794415416798357
S(d, r) # -2.513306124309698Positive log likelihoods happen!
# True vs. predictive
S(d, p) # -1.917322692203401
S(d, [2/3, 1/3])
# -1.9095425048844388# Deviance
deviance = lambda d, p: -2 * S(d, p)
S(d, p) # -1.917322692203401
deviance(d, p) # 3.834645384406802Regularization!

compare but don't select
# Mine (Python)
def sum_log_prob(a, b):
return max(a, b) + math.log1p(math.exp(0 - abs(a - b)))
# McElreath's (R)
log_sum_exp <- function( x ) {
xmax <- max(x)
xsum <- sum( exp( x - xmax ) )
xmax + log(xsum)
}Ulysses' compass