Berkeley Deep RL Bootcamp
Wednesday August 30, 2017
At its conclusion, Pieter Abbeel said a major goal of his 2017 Deep Reinforcement Learning Bootcamp was to broaden the application of RL techniques. Around 250 representatives from research and industry had just emerged from 22 scheduled hours over a Saturday and Sunday in Berkeley. Abbeel asked the attendees to report back with tales of applying algorithms they may not have known existed previously.
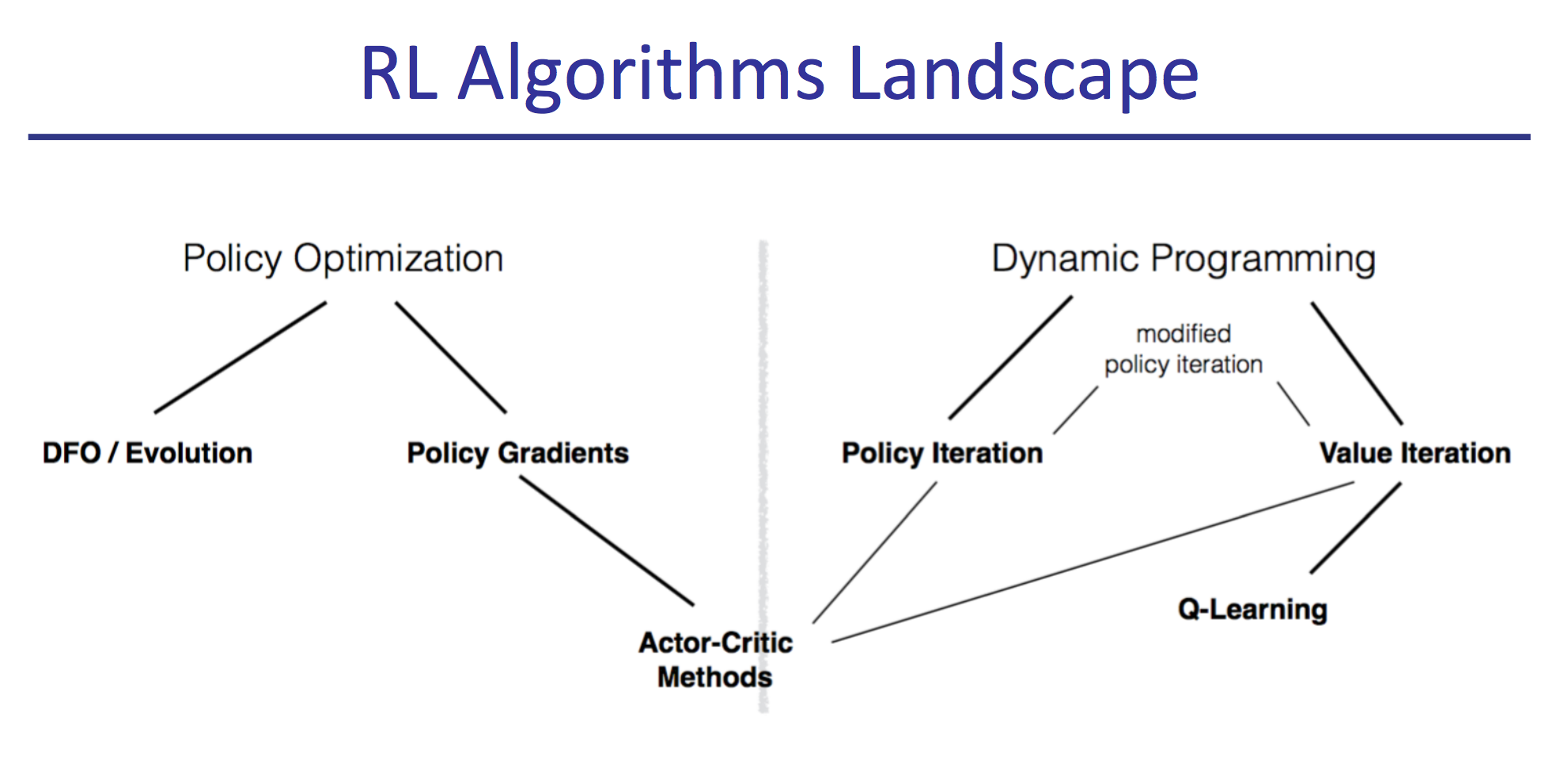
Instruction came from leaders of modern reinforcement learning research, all delivering their expertise within a framework that highlighted the large-scale structure of the field. I found their organizing diagram to be particularly helpful.
The reinforcement learning problem statement is simple: at every time step, an agent gets some observation of state \( s \), some reward \( r \), and chooses an action \( a \). So an agent is \( s,r \rightarrow a \), and reinforcement learning is largely about rearranging these three letters.
For example, the Q function is \( s,a \rightarrow \sum{r} \). You can learn that function from experience, and it nicely induces a policy \( s \rightarrow a \). If you use a ConvNet to learn the Q function, you can then publish in Nature.
Of the many good things about the bootcamp, I most valued getting a better conceptual feel for RL. It was also great to hear from experts about practical details, intuitions, and future directions. For all of these I particularly appreciated Vlad Mnih's sessions.
The concerns of RL illuminate deep architectures from unique angles. The big networks that win classification challenges don't win in RL, for example, possibly getting at something about the nature of neural net training and generalization. Vlad described how fixing their target Q-network was more important with the smaller nets they used in development than on their final networks. Wins with distributional RL may connect to a fundamental affinity of neural nets for categorical problems over regression problems.
Approaches like unsupervised auxiliary tasks prompt comparisons with how the brain might work. But even cutting-edge techniques with models (\( s,a \rightarrow s \)) and planning, like imagination-augmented agents and the predictron, do as much to highlight differences as similarities with how we think. RL is at least as close to optimal control as it is to AGI.
Reinforcement learning is home to a profusion of acronyms and initialisms that can be intimidating. As best I can, I've extended the Deep RL Bootcamp's diagram to include everything that was covered, together with a few terms common elsewhere and a set of expansions and links. For didactic resources, start from Karpathy's Pong from Pixels.
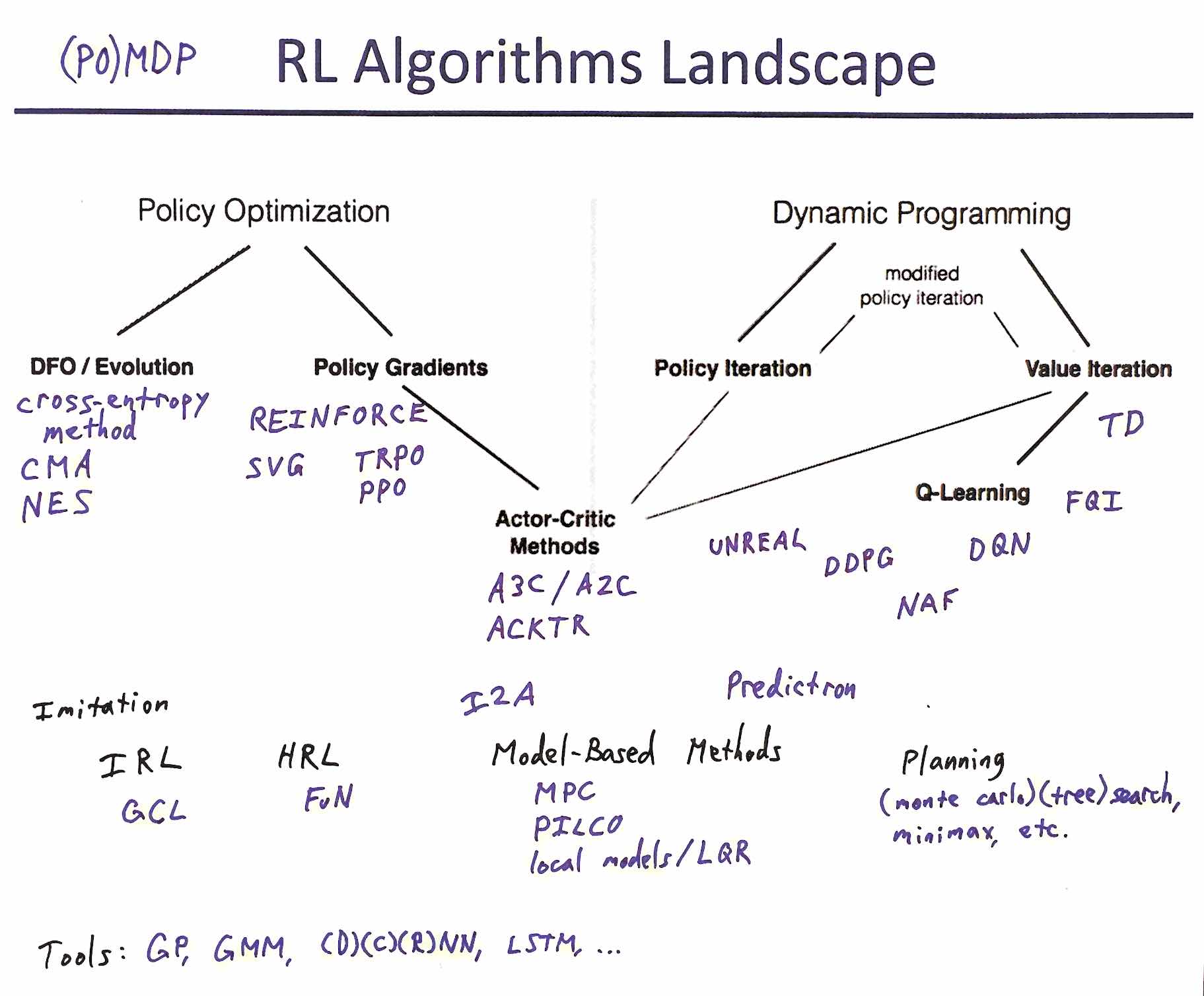
- (PO)MDP: (Partially Observable) Markov Decision Process
- DFO: Derivative-Free Optimization
- cross-entropy method
- CMA: Covariance Matrix Adaptation
- NES: Natural Evolution Strategy
- REINFORCE: REward Increment = Nonnegative Factor times Offset Reinforcement times Characteristic Eligibility
- TRPO: Trust Region Policy Optimization
- PPO: Proximal Policy Optimization
- SVG: Stochastic Value Gradients
- A3C: Asynchronous Advantage Actor Critic
- A2C: (Synchronous) Advantage Actor Critic
- ACKTR: Actor Critic using Kronecker-Factored Trust Region
- UNREAL: UNsupervised REinforcement and Auxiliary Learning
- TD: Temporal Difference (also \( TD(\lambda) \))
- FQI: Fitted Q Iteration
- DQN: Deep Q-Network
- DDPG: Deep Deterministic Policy Gradient
- NAF: Normalized Advantage Functions
- Imitation Learning
- IRL: Inverse Reinforcement Learning
- GCL: Guided Cost Learning
- HRL: Hierarchical Reinforcement Learning
- FuN: FeUdal Networks
- MPC: Model Predictive Control
- PILCO: Probabilistic Inference for Learning COntrol
- local models specifically as in Learning contact-rich manipulation skills with guided policy search
- LQR: Linear-Quadratic Regulator
- The Predictron: End-to-end learning and planning
- I2A: Imagination-Augmented Agent
- (Monte Carlo) (tree) search, minimax, etc.
- GP: Gaussian Process
- GMM: Gaussian Mixture Model
- (D/C/R)NN: (Deep/Convolutional/Recurrent) Neural Network
- LSTM: Long Short-Term Memory